
A lot of what I will be going through will reference this amazing 289 page behemoth document from Microsoft which can be downloaded from here:
Architecture for containerized .Net applications
I’ll be linking to blog posts, videos, and any interesting whitepapers I have found. Whilst also looking into how others have created, or transformed previous monolithic applications into multiple loosely coupled micro services.
As with anything this large and all engrossing, this will cover my journey through this process and anything I have learnt. If you have any other suggestions or ideas about what is written then feel free to leave comments below and I can make changes where necessary.
So lets get onto it.
What are Microservices?
Well first we need to start with simply what is a service and what is a system?
A service is in software terms is:
- owned, built, and run by an organisation
- is responsible for holding, processing, and/ or distributing particular kinds of data within the scope of a system
- can be built, deployed, and run independently, meeting defined operational objectives
- communicates with consumers and other services, presenting information using conventions and/or contract assurances
- handles failure conditions such that failures cannot lead to information corruption
- protects itself against unwanted access, and its information against loss
A set of services compromise a system
- A system is a group of services and systems, aiming to provide a combined solution for a well-defined scope.
- A system may appear and act as a service towards other parties.
- Systems may share services
- Consumers may interact with multiple systems
A service is not a specific set of languages or frameworks, it is a combination of these services to deliver a solution. It is not simply an API in a docker instance sat on a Linux container written in .Net, JavaScript or any other scripting language. It is independent of implementation choices.
So what is the difference between a service and microservice? Well microservices must be independently deployable, whereas SOA services are often implemented in deployment monoliths. SOA is an architectural pattern in which application components provide services to other components. However, in SOA those components can belong to the same application.
The most important thing to remember with Microservices is that they’re “Autonomous”
That means:
- A service owns all of the state it immediately depends on and manages
- A service owns its communication contract
- A service can be changed, redeployed, and/or completely replaced
- A service has a well-known set of communication paths
- Services shall have no shared state with others
- Don’t depend on or assume any common data store
- Don’t depend on any shared in-memory state
- No sideline communications between services
- All communication is explicit
It all boils down to remembering that Autonomy is about cross organisational collaboration. It’s ethos is that no single service is coupled to another!
Challenges and solutions for distributed data management
Defining Boundaries
The first challenge you will have when designing your microservice architecture is how to separate your current setup into autonomous chunks. You will need to define the boundaries of each microservice identifying decoupled data points and contexts within the same application. The goal is not to get the most granular separation possible, but the most meaningful separation needed for your domain, if you define a boundary and then find a high number of dependencies you will probably need to redefine again.
The emphasis is not on size but on business capabilities.
You should define your boundaries based on the Bounded Context pattern. In order to identify these a Domain Driven Design (DDD) or Context Mapping pattern can be used.
Consistency across multiple microservices
As each microservice is decoupled from others, it is a challenge to keep consistency of data across multiple microservices.
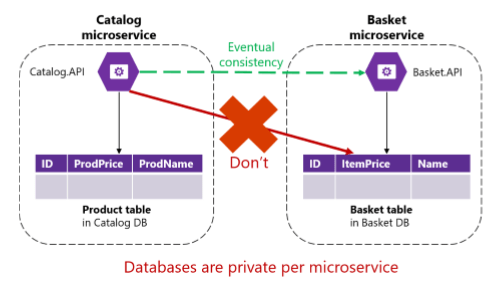
We can see above that when the price changes in one microservice we will have to propagate that change to the others. Usually this would involve a join or an API call to reflect this, however with each microservice having a private database we need to use eventual consistency based on asynchronous communication such as integration events.
Distributed systems communication and data retrieval
With potentially many decouple microservices running separately, it is a challenge to to pick the right solution with regards to querying data from these microservices in an optimal fashion.
When reading online and using the PDF attached at the top of the page Api Gateways are mentioned heavily when creating microservices as a way of grouping them together. Although this can be an easy approach to take, it is fundamentally against the core principles of microservices.
Firstly I’ll go through a quick history lesson on ESB (Enterprise Service Bus) and what this was, before talking about Api Gateways and how they are similar.
What is/was ESB (Enterprise Service Bus)
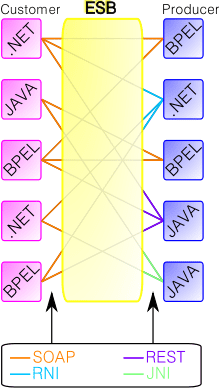
The ESB Model promised simplification through centralization
The entity service bus promised to make systems more simplified by have a central point dealing with everything, in smaller applications there are advantages to this pattern, however at scale many of the ESB advantages actually become its biggest weaknesses.
The ESB eventually becomes a bottleneck as it’s tightly coupled to the every part of the system, the dilemma is at scale, with mobile clients, lots of services, nobody is owning the centralised area which would require a change every time one of these services are updated, upgraded or changed entirely, this could/would result in downtime, and affect the whole system!
What is an Api Gateway
An API gateway falls in to the same sort of trap. It sits centralised dealing with multiple microservices. Clearly it’s not as large a behemoth as the ESB model, but changing microservice within the gateway would require changes in both the service and the gateway.
If they need to be used API Gateways should be segregated based on business boundaries and not act as an aggregator for the whole application.
Drawbacks of the API Gateway pattern
- The most important drawback is that when you implement an API Gateway, you are coupling that tier with the internal microservices. Coupling like this might introduce serious difficulties for your application. (The cloud architect Clemens Vaster refers to this potential difficulty as “the new ESB” in his “Messaging and Microservices” session from at GOTO 2016 that’s shown below.)
- Using a microservices API Gateway creates an additional possible point of failure.
- The API Gateway can represent a possible bottleneck if it is not scaled out properly
- An API Gateway requires additional development cost and future maintenance if it includes custom logic and data aggregation. Developers must update the API Gateway in order to expose each microservice’s endpoints. Moreover, implementation changes in the internal microservices might cause code changes at the API Gateway level. However, if the API Gateway is just applying security, logging, and versioning (as when using Azure API Management), this additional development cost might not apply.
This great conference mentioned above from Clemens Vaser that talks about Microservices and how API Gateways are a bad idea. He documents how we can fall into the same trap that we did with ESB’s and strongly argues against their use. I have also attached his slides from the presentation below in the Appendix.
In a monolithic application running on a single process, modules call one another using method or function calls. These can be strongly coupled using code such as new Class (), or can be loosely coupled by using Dependency Injection.
Either way, the objects are running within the same process. The biggest challenge when changing from a monolithic application to a microservices-based application lies in changing the communication mechanism.
A direct conversion from in-process method calls into Remote Process calls to services will cause an inefficient communication that will not perform well in distributed environments.
The challenges of designing a distributed system properly have been well documented; assumptions that are made by programmers can cause problems. These were penned by L Peter Deutsch and consist of:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
Please be aware, non of these examples listed are true, you should not fall in the trap of thinking that any of these is not worth thinking about and that they will deal with themselves. Each of these require code coverage to handle, making sure the code can handle network outages, packet loss, changes to security protocols etc.
More can be read about these fallacies here: 8 fallacies of distributed systems
There is not one solution, but several.
AMQP, HTTP or TCP
A microservices based application is a distributed system running on multiple processes or services, usually across multiple servers or hosts. Each service is typically a process. Therefore, services must interact using an inter-process communication protocol such as HTTP, AMQP, or a binary protocol like TCP, depending on the nature of each service.
Smart endpoints and dumb pipes
Is a term evocative of microservices and is a design principle that is tried and tested leveraging asynchronous communication mechanisms over complex system topology.
A design that is as decoupled as possible, choreographed by using RESTFUL and flexible event driven communications instead of a centralised orchestrator.
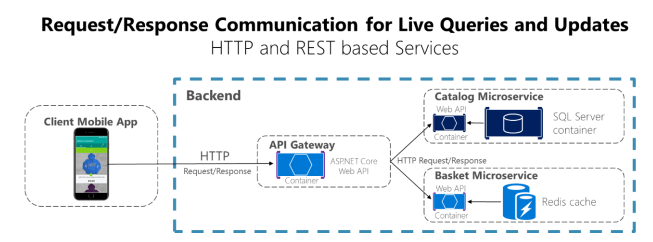
The two most common methods are using HTTP/S messages with API’s. This is a synchronous protocol, where the clients sends a request and waits for a response. This would usually use a Command Pattern where each request is processed by one service.
The other is lightweight asynchronous messaging protocols such as AMQP. Client code or messages don’t need to wait for a response, simply sending the message to a broker such as RabbitMQ where they then get handled by a separate process. The pub/sub approach is one such mechanism leveraging multiple receivers as the asynchronous nature means each request could be handled by one or more instances of services. The other is event driven communication usually implemented using a services bus with such options available as MassTransit, NServiceBus using queues or Azure Service Bus by using topics and subscriptions.
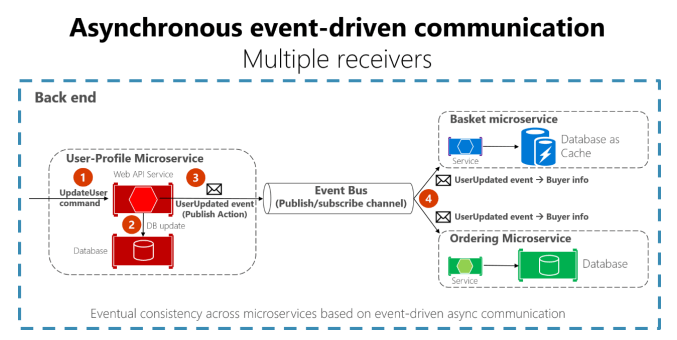
A comparison between these two approaches can be found here: Queues vs Topics and Subscriptions.
Communication between services
You should try to minimize the communication between your microservices.
The less communication between these, the better. Of course, sometimes you will have to integrate the microservices. The critical rule here is that the communications should be asynchronous and carried out by propagating data asynchronously, not depending on other internal microservices as part of the initial HTTP request/response.
You should never depend on synchronous communication between microservices, the goal is for each microservice to be autonomous and available to the client consumer, even if the other services that are part of the application are offline or corrupt. This means your architecture has to be resilient enough to handle when certain services fail
Synchronous operations, will mean performance is impacted. The more you add synchronous dependencies (like query requests) between microservices, the worse the overall response time will be at the client.
Microservice versioning, discovery and service registry
The benefits of the microservices model come at the cost of increased operational complexity, due to things like platform heterogeneity, the need for service discovery, and messaging and API call volumes.
A service API will need to change over time. When this happens, and especially when it’s a public API being consumed by multiple applications you cannot force uptake to this new contract. A versioning strategy must be put in place to keep both old and new versions available to your users.
The mediator pattern can split your implementations into independent handlers, and Hypermedia is great for versioning your services.
A service registry is needed as your URLs of each microservice needs to be resolved, wherever it may be running. In the same way DNS resolves an address your services need a unique name to be discoverable too. The service registry pattern is key to keeping your endpoints and service instances up to date.